- Unaligned Newsletter
- Posts
- AI Video Generation is Changing Fast
AI Video Generation is Changing Fast
On the Road to the Holodeck: The Emergence of Text-to-video Technology
Robert Scoble & Irena Cronin
February 21, 2024
Where is the Generative AI industry taking us over the next few years?
The Holodeck.
What the $*#$ do we mean by that?!
Take a look at the Apple Vision Pro. Realize how a 3D environment is all around you? By 2025, we’ll have a 3D environment that is fully under our control ALL of the time. New AI-display technology, Gaussian Splats, or Neural Radiance fields will bring us into a virtual world that looks and feels like we’re inside of a movie, where even characters that we generate will look like real people.
It’s a modern day holodeck, which included X, Y, Z in Star Trek.
Long story short: The future is closer than it's ever been.
To help, we’ve gathered 420 companies that are building various pieces of such a Holodeck. We made that list public on X: https://twitter.com/i/lists/1705695075014180922, so you can track this segment of the generative AI industry along with us. This week saw a major step toward such a thing. That makes up the bulk of this week’s newsletter.
Open AI just announced Sora, their text-to-video technology that can create up to 60 seconds of video from a text. Google announced Lumiere, an equally impressive competitor. They can only create seconds-long video, yet there are many artists that have combined these short videos to create minutes-long videos.
The leading companies so far for text-to-video have been Runway ML and Leonardo AI. New tech in this space seems to be announced everyday. Tik-Tok also launched their version called MagicVideo-V2. The race to take over Hollywood is on.

Open AI’s Sora can create up to a full minute of video

Google Lumiere can only do up to a few seconds
Text-to-video decodes semantics and emotions through text. The main goal is to streamline video content production. It’s going to have a hell of an impact on the entertainment business because it fundamentally revolutionizes the way content is created.
This tech lets anyone create professional grade video content without needing a deep understanding of traditional video production techniques. Bigger than that, no one will need a $200m budget to make a movie anymore. No more teams of experts and technicians, just pure content. The director and writers are even more in the drivers’ seat now than they were before.
Now we can craft animations, render simulations and produce lifelike scenes straight from a text description. It drastically lowers the barriers to producing movies, television series and video games.
The earliest entrypoint into Hollywood will be in the form of storyboarding. Visualizing pre-production concepts and getting the story of a new film together takes serious time. Often these concepts and animations are rudimentary and far off from the final product. Now we can have the same quality in pre-production as in post. The arts of film and TV are more than ever about the story.
Because the barriers to entry will drop exponentially, we’ll have imagination unleashed in its purest form.
Personalized Viewing Experiences
Text-to-video technology is going to make personalized content possible. Netflix’s algorithm recommends new content based on old content that they offered you. They then draw metrics based on viewership. Then the greenlight new programs based on whether it is similar to what viewers want.
Now that all changes. Instead of recommending new content, eventually new content will be made specifically for you. The content landscape will become even more individualized than it already is.
This is where the Apple Vision Pro comes in. There will be text-to-video applications that dynamically generate 3D immersive video. The video games of the future will almost feel like real life. No replay of a Role Playing Game will be like the previous play through. It’ll be truly reactionary based on what the user enjoys. It’s like entertainment cocaine.

Still taken from an Open AI Sora video generated from text
Think of what this means for educational and training content. One of the biggest issues in education is people can memorize the test. Or prepare for exact scenarios in training. With dynamic content, it will mean that students will be forced to actually think and engage with content. No more cheating! You can’t cheat in real life and you don’t get do-overs. Dynamic training will prepare the students of the future for the real world.
And now… a little history.
Early Attempts at Automated Video Generation
The foundational efforts in automated video generation date back to the late 20th and early 21st centuries, where the initial focus was primarily on creating simple animations and graphics based on predefined templates and basic scripting languages, an example which is below.

Still from a 1984 video entitled “High Fidelity” by Robert Abel and Associates
These early systems were limited by the technology of their time. They had minimal customization and lacked the ability to interpret complex textual inputs. They definitely couldn’t generate detailed visual narratives.
The process was heavily manual, with a significant reliance on human input for script creation, scene setting, and animation adjustments. Despite the limitations, these initial attempts laid the groundwork for future exploration and development in the field. The potential of automation was there, but not yet!
The Role of AI and Machine Learning in Advancing Text-to-Video Technology
The introduction of AI and ML into video generation marked a turning point. It ushered in an era of unprecedented growth and innovation.
AI and ML algorithms began to be applied to aspects of video production, from natural language understanding and sentiment analysis to image recognition and CGI generation.
They enabled systems to better interpret the nuances of text inputs, translating them into more accurate and contextually relevant visual representations.
Machine learning, has been especially important in teaching systems how to recognize patterns and understand relationships between different elements of a story. It lets you generate video sequences that are not only coherent but also visually appealing.
Deep learning, a subset of ML, further enhanced this capability by enabling more sophisticated image and video synthesis techniques. Examples are generative adversarial networks (GANs), which can create highly realistic images and scenes from textual descriptions.

Still taken from an Open AI Sora video generated from text
Key Breakthroughs That Have Enabled Current Capabilities
1. Natural Language Processing (NLP) Enhancements: Advances in NLP have improved a system's ability to analyze and understand complex textual inputs, giving more accurate interpretation of narratives and descriptions for video generation.
2. Generative Adversarial Networks (GANs): The development of GANs has revolutionized the field of computer vision. It allows for the generation of highly realistic images and videos from textual descriptions. This technology has been pivotal in bridging the gap between textual content and visual representation.
3. Computational Power and Data Availability: The recent huge increase in compute power and the availability of large datasets have facilitated the training of more complex and efficient models. This helps processing of massive datasets and the generation of high-quality video content at a much faster rate.
4. Integration of CGI and 3D Modeling: The integration of advanced CGI techniques and 3D modeling into text-to-video systems has allowed for the creation of more detailed and immersive video content, expanding the possibilities for storytelling and content creation.
Applications of Text-to-Video Technology
Use in Filmmaking and Animation
In the world of filmmaking and animation, text-to-video technology is reimagining the creative process. It serves as a transformative tool for directors and animators, enabling them to convert scripts into visual drafts or storyboards swiftly. This not only accelerates the pre-production stages but also offers a tangible vision of the final product early in the creative process. For animators, especially, this technology allows for rapid prototyping of scenes, character movements, and expressions, thereby enhancing the efficiency of the animation workflow and allowing for real-time feedback and revisions.
Video Games and Interactive Storytelling
Video game developers and narrative designers are using text-to-video technology to enrich interactive storytelling. This technology empowers them to create more dynamic and responsive game environments, where in-game narratives and cutscenes can be generated or altered based on player choices, making a more personalized gaming experience. It has the potential to streamline the game development process by automating the creation of in-game assets and environments. It could let developers focus on crafting more complex and engaging narratives, rather than in the drudgery of iterative development.
Personalized Video Content Creation for Platforms like YouTube and TikTok
Content creators on YouTube and TikTok are starting to use text-to-video to make personalized content fast. This could mean turning a blog post into a detailed video for viewers who prefer visual content. Or creating unique, tailored videos that address the specific interests of their audience segments. Quick, fast content production with little-to-no resources changes the game. Content creators will be harder pressed to create more engaging and individualized content for their viewers.
The Apple Vision Pro (AVP)
The AVP is a huge leap forward for content creation and consumption. It already does 3D photography and video. Text-to-video will integrate with Apple's ecosystem, harnessing the power of their hardware and software to create seamless experiences. It would potentially give creators, educators, and businesses the tools to transform written content into high-quality videos with ease, leveraging Apple's reputation for intuitive design and powerful performance.

Eventually AVP environments will be dynamically created on demand
Educational Content and Explainer Videos
Teachers and educational content creators can transform lesson plans and educational material into individually engaging explainer videos, making complex concepts easier to understand and retain. This is especially valuable in creating content for online courses and MOOCs, where visual aids can seriously enhance the learning experience.
Future Directions – Text-to-3D Video
Right now, in terms of text-to-3D, the best that could be done is creating text-to-3D imaging. An example of this is an image generated by Luma AI’s Genie below.
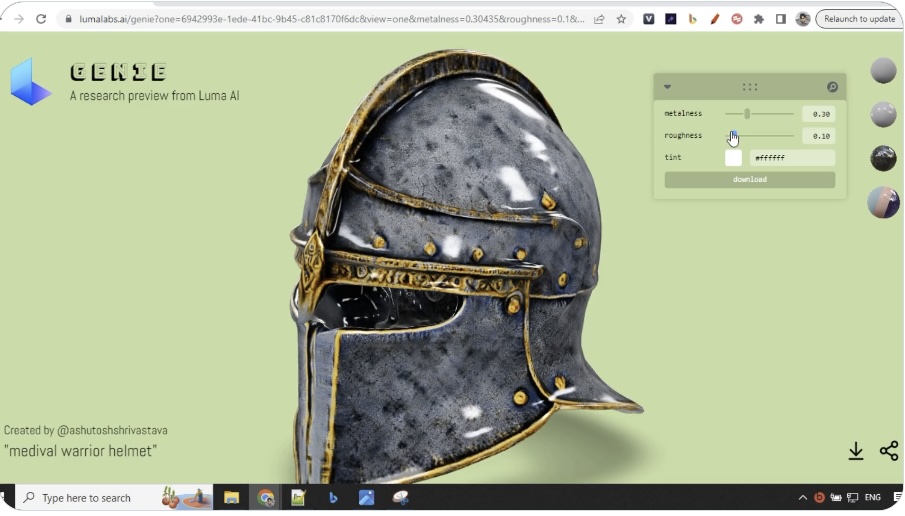
An example of a text-to-3D image generated from Luma AI’s Genie
Looking towards the horizon, the next evolutionary step for text-to-video technology is its expansion into the realm of text-to-3D video.
It would open a new world of virtual experiences, integrating depth and spatial relationships to produce content for VR, AR, and mixed reality (MR). As this stuff gets better, it will have an impact on tourism. Why travel in a plane for 12 hours to Europe when you can get an incredible tour of the coliseum from your living room. Obviously, we aren’t there yet. But we will be.
Conclusion
In summary, text-to-video is rapidly becoming an invaluable asset across industries. It enhances creativity, streamlines production, and offers personalized experiences.
As the technology matures and becomes more integrated with tools like the AVP, its applications will likely expand, paving the way for innovative uses that we can only begin to imagine. The promise of text-to-3D video calls for a future where the lines between text, video, and reality are increasingly blurred.
Note on Ethical Considerations and Societal Impact
The proliferation of text-to-video technology needs ethical scrutiny, particularly on deepfakes and misinformation. It also raises copyright and intellectual property issues, as it allows for easy copying of copyrighted material and would infringe on the original creators' rights.
Culturally, the effect will be even more profound. It has the potential to homogenize content across platforms, diluting the diversity of expression. We need robust verification mechanisms, strong legal frameworks, and higher public awareness to navigate these challenges. This technology is incredible. But it has to be done right and be constructive, rather than destructive.
Just Three Things
According to Scoble and Cronin, the top three relevant happenings last week
Open AI Sora
Open AI has announced its groundbreaking Sora—text-to-video technology that can produce up to 60 seconds of video. Other competitors, including Google’s Lumiere, Runway ML and Leonardo AI can just do seconds-worth of video. A limited number of people have current availability to the technology, with creators doing testing for OpenAI. Additionally, Sora is undergoing “red-teaming” which is ethical hacking to ensure Sora’s safety for the public. Open AI
Google Gemini 1.5
Google has introduced Gemini 1.5, the latest iteration of its AI model, hot on the heels of the release of Gemini 1.0 in December. This updated version comes with substantial improvements over the original, featuring a much longer context window, heightened understanding capabilities, and a general boost in performance. The Gemini 1.5 Pro version can run up to one million tokens in production—a huge increase from Gemini 1’s 32,000 tokens. The significance of this advancement lies in the expansion of the model's context window, which is measured in tokens. With an increased token capacity, the model can process a larger breadth of information, thereby enhancing the relevance and accuracy of its responses. Google Blog
Apple Integrating AI Into Its Xcode Programming Software, More
Apple's Xcode programming software is set to enhance its capabilities with new generative AI features, which are currently undergoing expanded internal testing, with a rollout expected for third-party developers within the year. Apple is also reportedly exploring the integration of generative AI into consumer products, envisioning applications such as AI-driven playlist generation in Apple Music, dynamic slideshow creation in Keynote, and advanced chatbot-like functionalities in Spotlight search. This move could revolutionize user interactions, allowing iOS and macOS users to engage in natural language dialogues with their devices to perform complex tasks, from obtaining weather updates to navigating app features. We feel this is just the beginning of what Apple will be announcing in terms of AI initiations. The Verge