- Unaligned Newsletter
- Posts
- Understanding Reinforcement Learning: An Easy Guide
Understanding Reinforcement Learning: An Easy Guide
Robert Scoble & Irena Cronin
May 23, 2024
Reinforcement learning (RL) is like teaching a dog new tricks but with computers and robots. It’s all about learning from rewards and getting better over time by interacting with the world. Whether it's making smarter robots or creating powerful game-playing AI, RL is a fascinating and powerful tool in the AI toolkit.
Key Concepts in Reinforcement Learning
To understand RL, here are some key ideas:
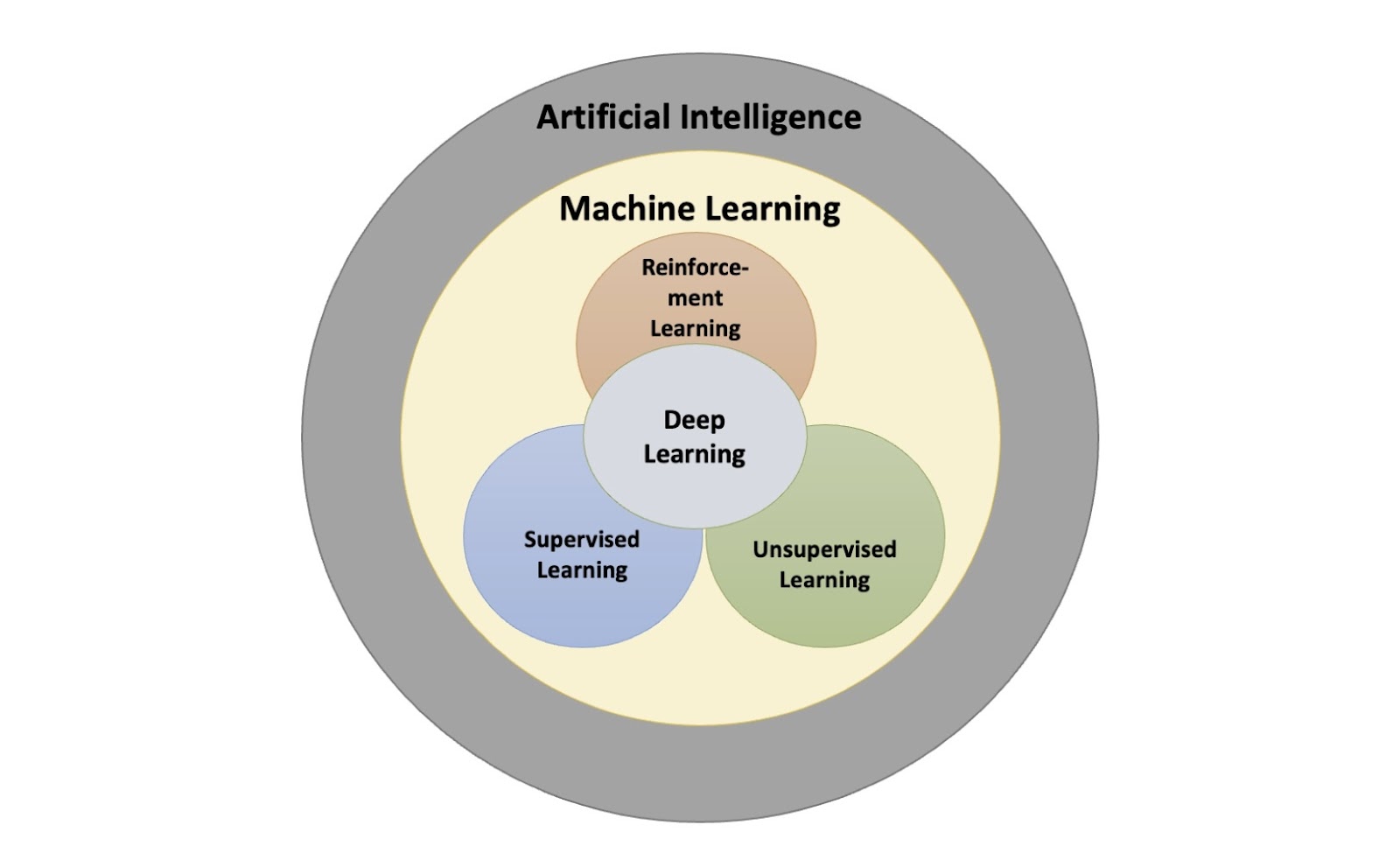
Agent and Environment: The agent is the learner or decision-maker, like a robot or a computer program. The environment is everything the agent interacts with, like a room the robot is in or a game the computer is playing.
Action: Actions are the things the agent can do. For example, a robot can move forward, turn left, or pick up an object.
State: The state is the current situation of the agent. For instance, the robot's state might include its position and what it can see.
Reward: A reward is a signal telling the agent how well it did after taking an action. Positive rewards mean it did something good, and negative rewards mean it did something bad. The goal is to get as many positive rewards as possible.
Policy: A policy is a strategy the agent uses to decide what action to take next. It’s like a set of rules or a plan.
Value Function and Q-Function: The value function estimates how good a particular state is in terms of future rewards. The Q-function estimates how good an action taken in a particular state is, leading to future rewards.
How RL Works
At its core, RL is about an agent making decisions, learning from the results, and improving over time. Here is the process step by step:
1. Starting Point
The journey of an RL agent begins with little to no knowledge about the environment it will interact with. This initial phase involves the agent making random guesses or following a simple rule set. Imagine a baby learning to walk. Initially, the baby doesn't know what to do and might fall several times. Similarly, the RL agent starts by trying out random actions to see what happens.
2. Interaction
Next, the agent begins to interact with its environment. This could be a physical environment like a maze or a digital one like a video game. The agent takes an action based on its current understanding or policy. For example, a robot might decide to move forward, turn left, or pick up an object. Each action is like a step in the learning process, and the agent's goal is to explore the environment to gather information.
3. Feedback
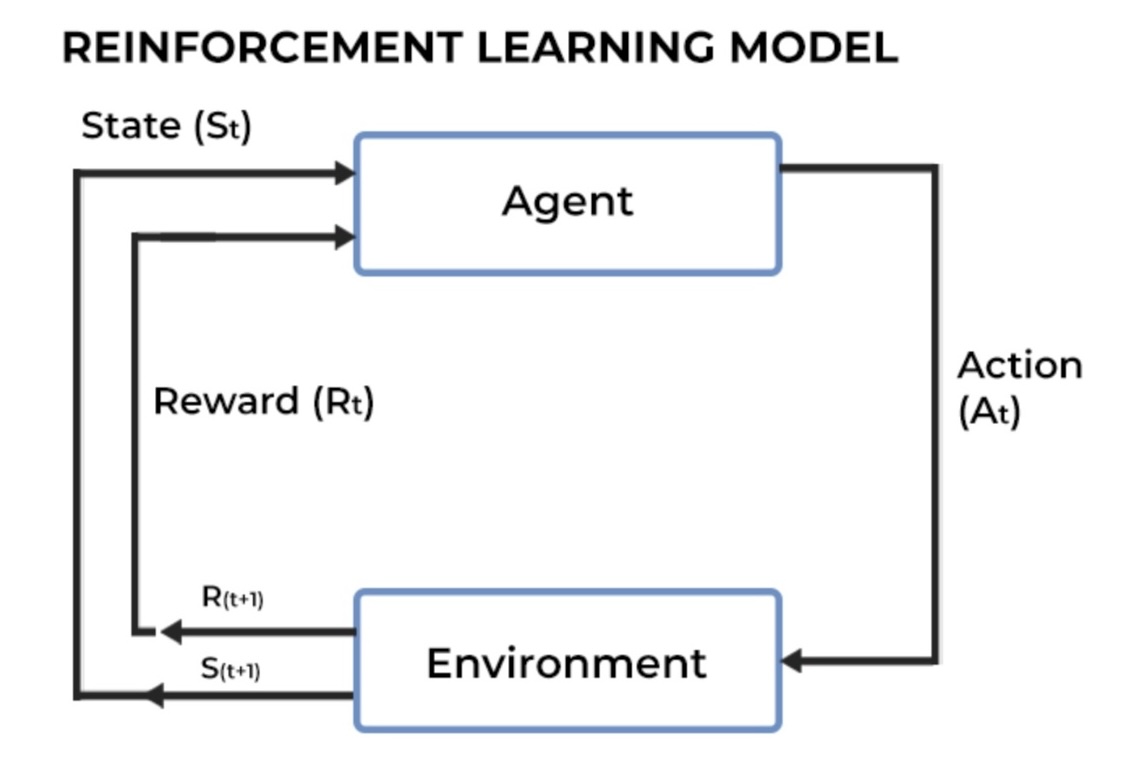
Once the agent takes an action, the environment responds. This response includes two critical pieces of information: a new state and a reward. The new state describes the current situation after the action, similar to how moving a chess piece changes the game board. The reward is a signal that tells the agent how good or bad the action was. Positive rewards encourage the agent, while negative rewards indicate mistakes. This feedback loop is crucial because it helps the agent learn from its experiences.
4. Learning
With the feedback from the environment, the agent begins to learn and update its strategy or policy. This is similar to a student revising their notes after receiving corrections from a teacher. The agent uses algorithms to adjust its actions to maximize future rewards. Over time, it starts to recognize which actions lead to better outcomes. For instance, if moving towards the light in a maze often leads to higher rewards, the agent will start favoring that direction.
5. Repeating
The process of taking actions, receiving feedback, and learning continues in a loop. The agent repeatedly interacts with the environment, constantly refining its policy. This repetition is essential for improvement. Just as practice makes perfect for humans, repeated interactions help the RL agent become better at making decisions. Over time, the agent's performance improves significantly, and it can handle more complex tasks with greater efficiency.
Real-World Example: Learning to Play a Game
Consider the chess example: teaching an AI to play a game like chess. Initially, the AI knows nothing about the game rules. It makes random moves, some of which are terrible. However, each game it plays provides feedback on which moves are good (leading to winning positions) and which are bad (leading to losses). The AI uses this feedback to update its strategy, gradually learning the best moves through thousands or even millions of games. Eventually, the AI becomes proficient and can play at or above human levels.
Real-World Applications of Reinforcement Learning
By allowing machines to learn from their experiences, RL opens up a world of possibilities across various industries. Here are some of the most exciting applications of RL in today's world:
Robotics
Robotics is one of the most thrilling fields where RL is making a huge impact. Imagine robots learning to do tasks by themselves, just like how children learn through trial and error.
Walking and Locomotion: Robots can now learn to walk or run by receiving feedback on their movements. They adjust their gait over time, becoming more efficient and stable, even on tricky surfaces.
Manipulation: In factories, RL helps robots learn how to pick up and handle objects with precision. This is super useful for tasks that involve delicate or oddly shaped items.
Navigation: RL enables robots to navigate through complex environments, avoiding obstacles and finding the best paths. This is crucial for robots working in warehouses, hospitals, and even space missions.

Gaming
The gaming industry has been a playground for RL, pushing AI to new heights.
Strategy Games: RL has created AI that can compete with, and sometimes beat, human players in games like chess and Go. These games require deep strategic thinking and planning, which RL excels at by learning from countless games.
Video Games: In video games, RL is used to develop smart, adaptive opponents that provide a more challenging and engaging experience for players. AI agents have even reached professional levels in games like Dota 2 and StarCraft II.
Game Development: RL also helps in the game development process by optimizing game design and balancing gameplay elements, ensuring a better experience for players.
Finance
The finance sector is leveraging RL to enhance trading strategies and investment management.
Automated Trading: RL algorithms can analyze massive amounts of market data to make profitable trades. These systems adapt to changing market conditions, constantly improving their strategies.
Portfolio Management: RL helps in optimizing investment portfolios by balancing risk and return. It continuously learns from market trends to adjust investments for maximum gain with minimal risk.
Fraud Detection: RL is also used to detect fraudulent activities by identifying unusual patterns in financial transactions, making financial systems more secure.
Healthcare
Healthcare is undergoing a transformation with RL, making treatments more personalized and processes more efficient.
Personalized Treatment Plans: RL algorithms can create personalized treatment plans for patients by analyzing their medical history and responses to treatments. This ensures that patients receive the most effective care tailored to their needs.
Drug Discovery: RL speeds up the drug discovery process by predicting the effectiveness and safety of new compounds. This helps in identifying promising drug candidates much faster.
Medical Imaging: RL improves the accuracy of medical imaging techniques like MRI and CT scans by enhancing image quality and reducing noise, aiding doctors in making better diagnoses.
Self-Driving Cars
Self-driving cars are one of the most talked-about applications of RL. These cars rely heavily on RL to navigate roads and make real-time decisions.
Navigation and Control: Self-driving cars use RL to learn optimal driving strategies, including lane changes, merging, and adhering to traffic rules. They get better at driving by continuously learning from their environment.
Safety: RL algorithms help autonomous vehicles anticipate and react to potential hazards, such as sudden stops by other cars or pedestrians crossing the street, enhancing overall safety.
Efficiency: RL optimizes the energy consumption of self-driving cars by learning efficient driving patterns, which is especially important for electric vehicles to maximize battery life.
Popular Algorithms in RL
Here’s a look at some of the most popular RL algorithms:
Q-Learning
Q-learning is a classic and widely used RL algorithm. It’s like the bread and butter of RL methods because it’s simple and effective.
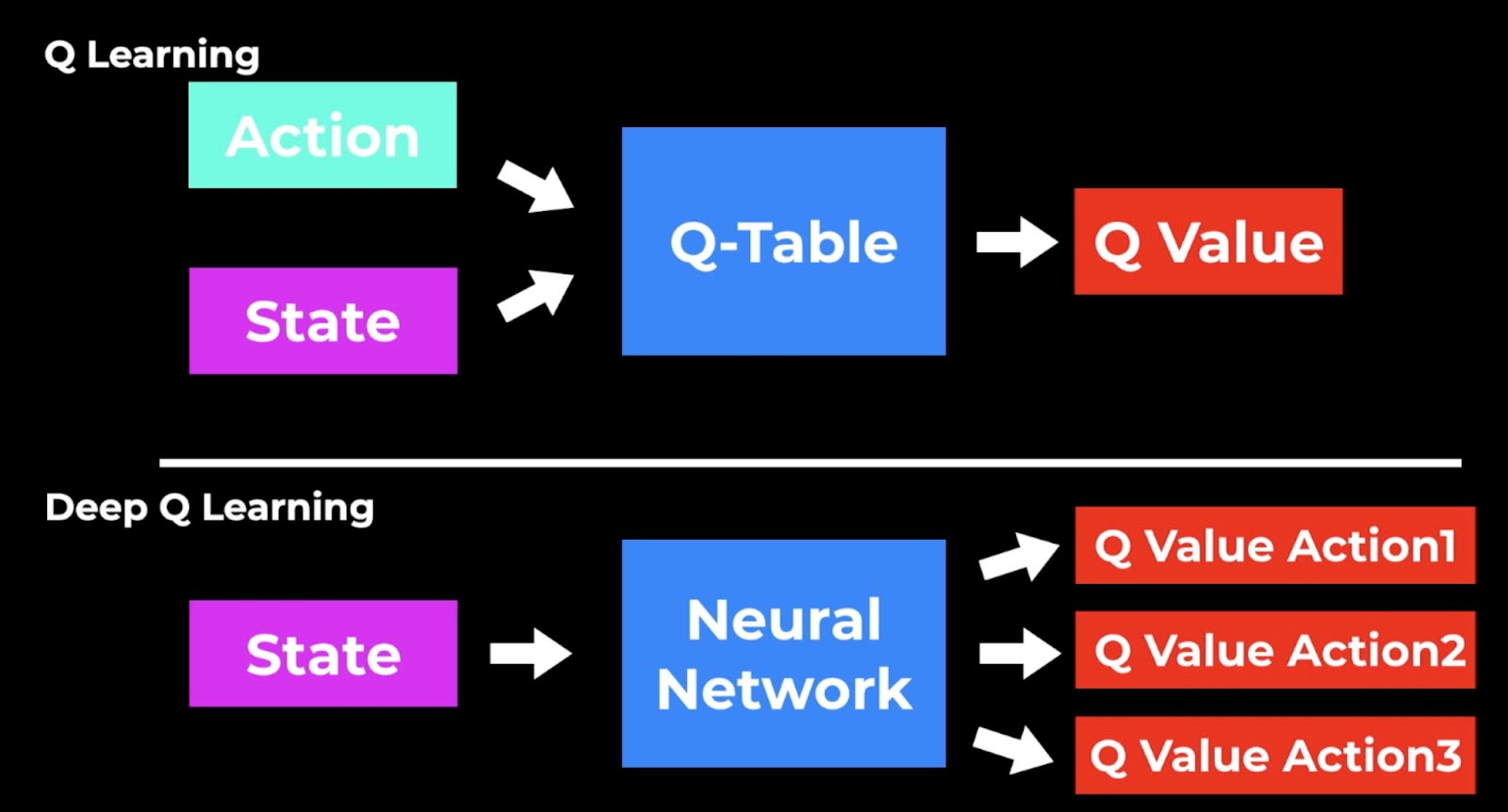
How It Works: Q-learning uses something called a Q-table. Think of it as a big spreadsheet where each combination of a situation (state) and an action gets a score (Q-value). This score tells the agent how good or bad taking that action in that situation is likely to be. The agent keeps updating these scores based on the feedback it gets from the environment.
Strengths: The best part about Q-learning is its simplicity. It works well for problems where the number of possible situations and actions is limited. Plus, it doesn’t need to know anything about how the environment works—it learns purely from the feedback it gets.
Deep Q-Networks (DQN)
DQN takes Q-learning to the next level by using deep neural networks. This makes it possible to handle much more complex environments, like video games.
How It Works: Instead of using a simple table, DQN uses a neural network to estimate the Q-values. This network looks at the current situation (state) and predicts the scores for all possible actions.
Experience Replay: One clever trick DQN uses is called experience replay. The agent stores its experiences (situations, actions, rewards, and outcomes) in a memory buffer and randomly samples from this buffer to learn. This helps break the correlation between consecutive experiences and makes learning more stable.
Target Network: To further stabilize learning, DQN uses a separate target network that updates periodically. This reduces sudden shifts in learning and helps the agent improve steadily.
Strengths: DQN is a powerhouse for handling complex, high-dimensional environments where a simple Q-table would be impractical due to the sheer number of possible situations.
Policy Gradient Methods
Policy gradient methods take a different approach by directly learning a policy, which maps situations to actions, instead of learning the value of actions.
How It Works: These methods optimize the policy by adjusting its parameters to maximize the expected reward. The policy is usually represented as a probability distribution over actions, which is defined by a neural network.
Strengths: Policy gradient methods are great for problems with continuous actions—where actions aren’t just a set of discrete choices but can take any value. This makes them ideal for tasks in robotics and other areas where precise control is needed.
Actor-Critic Methods
Actor-critic methods combine the best of both value-based and policy-based approaches by using two components: the actor and the critic.
How It Works: The actor decides which action to take based on the policy, while the critic evaluates the action by estimating its value.
Actor: Learns and updates the policy based on feedback from the critic.
Critic: Learns the value function and provides feedback to the actor about the quality of the actions taken.
Advantage Function: The critic often uses an advantage function to provide more detailed feedback, showing how much better or worse an action is compared to the average action in a given situation.
Strengths: Actor-critic methods combine the stability of value-based methods with the flexibility of policy-based methods, making them effective for a wide range of applications, including those with continuous and high-dimensional action spaces.
Reinforcement learning offers a variety of powerful algorithms, each tailored to different types of problems. Q-learning and DQN are fantastic for simpler and more complex environments, respectively. Policy gradient methods excel in continuous action spaces, while actor-critic methods provide a balanced approach for various tasks. By understanding and using these algorithms, smarter agents can be made that learn and adapt to their environments, solving real-world problems with increasing efficiency and sophistication.
Challenges in RL
As with any cutting-edge technology, there are significant hurdles that researchers and practitioners must overcome to fully realize its potential. Here are some of the key challenges in RL:
Exploration vs. Exploitation
One of the most fundamental challenges in RL is balancing exploration and exploitation.
Exploration: Exploration is all about trying new things to discover which actions yield the best rewards. Imagine you’re at a new restaurant and you want to try different dishes to find out what you like best. In RL, exploration involves the agent experimenting with various actions to gather information about their potential rewards. For example, a robot might need to try different paths to find the shortest route through a maze.
Exploitation: On the other hand, exploitation means using the knowledge you already have to maximize rewards. Going back to the restaurant analogy, once you find a dish you love, you might keep ordering it every time you visit. In RL, exploitation involves the agent consistently choosing actions that it has learned are the most rewarding. For example, once the robot learns the shortest path, it will stick to that route to minimize travel time.
The Dilemma: The tricky part is knowing when to explore and when to exploit. Too much exploration can be inefficient and slow down the learning process, while too much exploitation can prevent the agent from discovering potentially better actions. Balancing these two aspects is crucial for effective RL. This balance is often managed using strategies like epsilon-greedy, where the agent mostly exploits but occasionally explores, or using more sophisticated approaches like upper confidence bound (UCB).
Data Requirements
Another significant challenge in RL is the need for vast amounts of data to learn effectively.
Big Data Needs: RL algorithms often require large amounts of interaction data to learn good policies. This means the agent needs to experience many different situations and receive feedback on its actions. For example, a self-driving car needs to experience various driving conditions, like heavy traffic, rain, or icy roads, to learn how to handle them all effectively. In some cases, this can mean millions of interactions, which can be time-consuming and resource-intensive.
Simulation vs. Real World: While simulations can generate large amounts of data relatively quickly, real-world applications can’t always rely solely on simulations. For instance, training a physical robot requires real-world interactions, which are slower and costlier than virtual simulations. Gathering data in the real world is often impractical, posing a significant challenge for RL applications. Additionally, simulations may not capture all the nuances of real-world environments, leading to a gap between simulated and real-world performance.
Complexity
The complexity of certain environments and tasks can make RL particularly challenging.
High-Dimensional Spaces: Some RL problems involve high-dimensional state or action spaces. For example, controlling a humanoid robot involves many joints and possible movements, leading to a vast number of potential states and actions. Each additional degree of freedom adds to the complexity, making it harder for the RL algorithm to learn effective policies. Learning in such high-dimensional spaces is both complex and computationally expensive, requiring advanced techniques and significant computational resources.
Long-Term Dependencies: Some tasks require the agent to make decisions that will only show their value in the long run. For instance, in a strategy game, early moves might not pay off until much later in the game. RL agents need to learn these long-term dependencies, which adds another layer of complexity to the learning process. This is particularly challenging because the agent must maintain a balance between immediate rewards and future benefits, often requiring sophisticated planning and foresight.
Stability and Convergence: Ensuring that RL algorithms converge to a stable solution can be challenging. Training can be unstable, especially in complex environments, leading to oscillations or divergence in learning. For example, in financial trading, market conditions can change rapidly, causing the RL model to struggle with finding a consistent strategy. Techniques like experience replay, target networks, and regularization are often employed to address these issues, but they add complexity to the training process.
Reinforcement learning holds immense promise for transforming various industries, from robotics and healthcare to finance and autonomous driving. However, it's not without its challenges. Balancing exploration and exploitation, meeting data requirements, and managing complexity are significant hurdles that researchers and practitioners must address. By understanding and tackling these challenges, we can unlock the full potential of RL and create smarter, more adaptive AI systems. As technology advances, ongoing research and innovation will continue to push the boundaries of what RL can achieve, paving the way for exciting new applications and solutions. Whether it’s teaching robots to navigate complex environments or developing AI that can master strategic games, overcoming these challenges is key to harnessing the power of RL.
Just Three Things
According to Scoble and Cronin, the top three relevant and recent happenings
Open AI’s Departures and Anthropic’s Gain
Two leaders of Open AI’s superalignment team, Ilya Sutskever and Jan Leike, have left the company. Following that, Open AI made a statement about the company’s allegiance to safety. X is ablaze with gossip as to exactly why the two have left. We are sure here where there’s smoke, there is fire. In other news, Instagram co-founder Mike Krieger has joined Anthropic as Chief Product Officer. Vox, CNBC
Sony Music’s Official Complaint Regarding GenAI
As the world's leading music publisher and home to artists such as Beyoncé and Adele, Sony Music has initiated contact with over 700 entities, including major companies like Google, Microsoft, and OpenAI. This inquiry aims to determine if these companies have incorporated Sony's songs into their artificial intelligence system developments. The publisher's goal is to prevent these firms from using its music for training, developing, or earning revenue through AI without obtaining permission. This issue is really complicated and we think it will prove to be difficult to resolve this issue. Deadline
Anthropic Allows Minors to Use Third-Party Apps
Anthropic is modifying its policies to permit minors to access its generative AI systems under specific conditions. The company revealed on its official blog on Friday that it will allow teenagers and preteens to use third-party applications (but not its own) that utilize its AI models. This is contingent upon the app developers implementing designated safety measures and clearly informing users about the Anthropic technologies being used. Google has already allowed Gemini to be used by teens in selected countries. This is just the beginning of GenAI companies finding ways to capture the teen and preteen market. TechCrunch
Scoble’s Top Five X Posts




